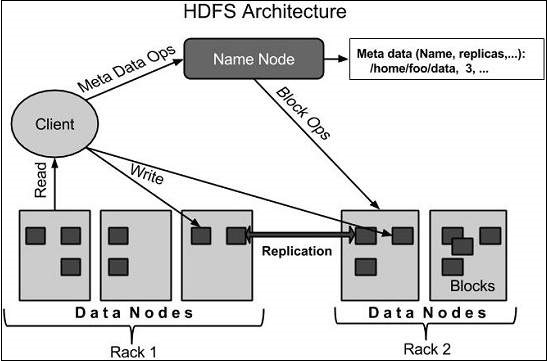
HDFS를 정리해 봤으니 이제 YARN을 정리해봅니당
1. YARN
- Yet Another Resource Negotiator의 약자. 0.23대 버전에서 소개되어 2.0버전을 이끌게 되었습니다. (MRv2라고도 합니다.)
- 분산 클러스터 환경에서 자원 관리에 대한 부분을 모두 YARN에게 맡김으로서 MR이 아닌 다른 서비스에서도 사용 가능하도록 구성되었습니다.
2. Architecture
1) Resource Manager(RM)
- 마스터 노드에 존재하며, 기본적으로 한개만 존재하지만 HA를 위해 여러개가 존재할 수 있습니다.
- 클러스터 전체 노드들과 통신하면서 상태를 조절하기 때문에, 개별 노드에 독립적으로 구성하여 병목이 발생하지 않게 해야 합니다.
- 클러스터 내의 자원을 총괄하여 관리합니다.
- 어플리케이션이 실행될 때, 필요한 YARN 클러스터 내부의 리소스를 할당해줍니다.
2) Node Manager(NM)
- 클러스터 내 개별 노드에서 각각 동작합니다.
- 리소스 매니저에게 각 노드의 상태 정보를 제공합니다.
- 어플리케이션이 실행될 때, 컨테이너가 생성되는데 이를 실행할 환경을 구성하고 컨테이너의 자원 사용 상황을 주시하여 요청한 리소스를 넘는지 확인합니다. (넘으면 kill 시킵니다.)
3. Process

- 마스터 노드에 리소스 매니저가 있습니다.
- 각 워커 노드에 노드 매니저가 있습니다.
- 리소스 매니저는 어플리케이션 매니저(Applications Manager, 이하 ASM)와 스케쥴러를 포함하고 있습니다.
- 외부로부터의 요청이 없으면 노드 매니저는 자신의 상태를 계속해서 리소스 매니저에 전송하고, 리소스 매니저는 클러스터 전체 자원 상황만 관리하고 있습니다.
- 이제 어플리케이션이 클라이언트로부터 제출됩니다. 시~작!
- 사용자가 어플리케이션을 제출, 리소스 매니저의 ASM이 이를 담당하게 됩니다.
- ASM은 클러스터 어딘가에 어플리케이션 마스터(Application Master, 이하 AM)를 생성합니다. 또한, ASM은 AM이 비정상 종료되면 다시 시작시켜서 작업을 진행할 수 있도록 합니다.
- AM은 RM에 있는 스케줄러에 자원을 요청하고 RM내의 스케줄러는 전체 클러스터의 자원 상황을 고려하여 어떤 노드에서 작업을 시작하면 좋을지 판단하여 알려줍니다.
- AM은 RM으로부터 전달받은 작업을 수행할 노드의 NM에게 컨테이너를 요청합니다.
- NM은 해당 노드에 어플리케이션의 세부 작업을 진행할 컨테이너를 생성하고 환경을 구성해줍니다.
- 컨테이너는 진행 상황을 AM에게 전달합니다. 만약, 이 단계에서 장애가 발생하면 3번부터 다시 시작합니다.
- 작업이 종료됩니다. AM과 컨테이너는 필요하지 않으므로 종료되고, 잡 히스토리 서버를 두어 작업 로그를 유지합니다.